Uso de computação gráfica na criação de bases de dados sintéticos para treinamento de modelos de inteligência artificial

A Revista Eletrônica PesquisABC possui o seguinte registro ISSN: 2675-1461
Felipe Nunes Carbone de Carvalho, Bruno Augusto Dorta Marques
Centro de Matemática Computação e Cognição (CMCC), Universidade Federal do ABC (UFABC)
Endereço: Av. dos Estados, 5001, Bangu, Santo André/SP, CEP 09280-560
Resumo: Este trabalho apresenta um software personalizado para criar bases de dados sintéticas contendo imagens e informações semânticas. O objetivo é facilitar o treinamento de modelos de inteligência artificial, especialmente em situações onde obter imagens reais é desafiador. A ferramenta foi desenvolvida utilizando o motor gráfico Unity e emprega a técnica de Randomização de Domínio (RD) para sintetizar cenas 3D. A RD gera variações aleatórias em texturas, modelos 3D, iluminação, ambiente e terreno. Isso permite que o usuário crie bases de dados com objetos 3D personalizados. Ao focar nas características essenciais dos elementos estudados, o software permite que redes neurais sejam treinadas de forma eficiente, evitando o custo temporal e financeiro associado à criação de imagens fotorrealistas. Essas imagens geralmente exigem síntese manual e artística de modelos 3D e texturas, ou a coleta de dados reais. O diferencial deste trabalho é a democratização da implementação da RD. Mesmo pessoas com pouca familiaridade no método podem criar bases de dados de imagens eficientes com mínimo esforço.
Palavras-chave: dataset sintético; computação gráfica; inteligência artificial; aprendizado de máquina; randomização de domínio
Abstract: This work presents a custom software for creating synthetic databases containing images and semantic information. Its purpose is to facilitate the training of artificial intelligence models, especially in cases where obtaining real images is challenging. The tool was developed using the Unity game engine, employing the Domain Randomization (RD) technique to synthesize 3D scenes. RD generates random variations in textures, 3D models, lighting, environment, and terrain, allowing users to create databases with custom 3D objects. By focusing on the essential characteristics of the studied elements, the software enables efficient training of neural networks, avoiding the time and financial cost associated with creating photorealistic images. Such images typically require manual and artistic synthesis of 3D models and textures or real-world data collection. The key differentiator of this work is the democratization of RD implementation, allowing even those unfamiliar with the method to create efficient image databases with minimal effort.
Keywords: synthetic dataset; computer graphics; artificial Intelligence; machine learning; domain randomization
Este endereço de email está sendo protegido de spambots. Você precisa do JavaScript ativado para vê-lo., Este endereço de email está sendo protegido de spambots. Você precisa do JavaScript ativado para vê-lo.*
* https://orcid.org/0009-0005-0929-0125
O problema da obtenção de dados
Nos últimos anos, muito tem se falado sobre inteligência artificial e as grandes possibilidades que este tipo de tecnologia gera para a sociedade, entretanto há algo de suma importância para a criação deste tipo de modelo e que por muitas vezes passa despercebido aos olhos de muitos: Os dados de treinamento, sem os quais estes modelos não podem aprender.
Entre os métodos de aprendizado de máquina mais utilizados atualmente está o aprendizado supervisionado. Nessa metodologia, os modelos são construídos e treinados para uma aplicação específica a partir de exemplos. Cada exemplo consiste em uma amostra x e um rótulo y que a caracteriza. Esses exemplos formam um conjunto de dados, conhecido como dataset [2].
Para realizar o treinamento de modelos de aprendizado supervisionado é necessária uma grande quantidade de exemplos, o que nem sempre é algo simples de se conseguir. Para casos onde os exemplos consistem de imagens, essa tarefa pode ser ainda mais desafiadora, pois em alguns casos o processo de rotular as imagens pode exigir informações individuais para cada pixel, o que para milhares de exemplos pode tornar-se inviável.
Por essa razão o uso de computação gráfica para criar esses datasets de maneira sintética tem sido amplamente utilizado, uma vez que em um ambiente virtual podemos ter um grande controle sobre o ambiente, sendo capazes de alterar aspectos como posição da câmera, escala e rotação de modelos 3D, além de rótulos por pixel de informações espaciais e semânticas, tais como profundidade, material, classe de objetos, entre outros.
A Randomização de Domínio (RD) [7] é uma técnica utilizada na criação de conjuntos de dados de imagens artificiais. Ela envolve a geração de imagens sintéticas que não precisam ser fotorrealistas, mas possuem uma ampla variedade de características em seu ambiente (domínio). Mesmo que essas imagens sejam pouco semelhantes à realidade, um modelo de aprendizado supervisionado treinado com elas é capaz de generalizar para dados reais, mesmo sem ter visto uma imagem real durante o treinamento.
Por que implementar a RD?
A técnica de RD foi proposta pela primeira vez nos moldes atuais por [7], ao tentar treinar um braço robótico para identificar e movimentar objetos sobre uma mesa, e desde então, a RD tem sido utilizada em diversas aplicações. Um desses casos é [8], que buscou testar a eficácia de seu dataset criado via RD contra duas outras bases de dados existentes. O objetivo era treinar um modelo para reconhecimento de veículos no trânsito e como já existiam dois outros datasets para este fim, sendo um criado com imagens reais e o outro com imagens geradas virtualmente com modelos 3D realistas, os pesquisadores puderam comparar o desempenho de seu modelo com essas duas formas alternativas de criação de bases de dados. O resultado, mostrou que o modelo treinado com RD foi capaz de superar em acurácia não apenas redes neurais treinadas com os datasets real e sintéticos separadamente, mas também uma terceira rede treinada com abas simultaneamente, demonstrando que mesmo sendo uma opção menos custosa do que as outras duas opções, a RD possui potencial para igualar ou até mesmo superar os métodos alternativos.
Criação de um software gerador de datasets sintéticos
A técnica de Randomização de Domínio tem ajudado diversos cientistas a resolver o problema da obtenção de datasets de imagens. No entanto, ainda persiste um problema: Em geral, ainda se faz necessário implementar para cada tipo de problema um software distinto para gerar a randomização, o que demanda um extensivo tempo e especialização. Pensando em ajudar a resolver este problema, este trabalho buscou criar um software livre que permite a criação de datasets randomizados sobre variados tipos de objetos, de maneira simples e rápida, exigindo do usuário apenas um modelo 3D de exemplo para cada objeto que queira randomizar.
Para desenvolver o software, utilizamos o motor gráfico Unity [6]. Embora originalmente projetado para criar jogos, o Unity oferece a vantagem de executar em altas taxas de quadros por segundo, além de fornecer ferramentas úteis no processo de geração de imagens, permitindo a criação eficiente de um dataset robusto em pouco tempo. Embora os motores de jogos possam ter qualidade gráfica inferior em comparação com ferramentas específicas para geração de imagens, essa diferença pode não ser relevante para a Randomização de Domínio (RD), visto que a RD não requer imagens fotorrealistas; portanto, priorizamos o alto desempenho e velocidade proporcionados pelo Unity.
Ao criar o software (ao qual chamamos “ABCDataset”) implementamos a randomização de 7 parâmetros no ambiente:
- Objetos de estudo.
- Textura de modelo e terreno.
- Posição e ângulo de câmeras.
- Iluminação.
- Formas de terreno.
- Efeitos de shader.
- Mapas de ambiente.
Esses parâmetros de randomização podem ser controlados de maneira simples e intuitiva através da interface de usuário do nosso sistema. Dessa forma o usuário apenas precisa adicionar o modelo que quer randomizar, selecionar os parâmetros desejados e a quantidade de imagens a serem geradas. Após isso basta iniciar a geração e o software cria o dataset automaticamente.

Figura 1. Demonstração do processo de criação de imagens sintéticas com o ABCDataset. À esquerda os modelos inseridos pelo usuário, ao meio, as transformações que o programa gera, e à direita, as imagens finais.
Testando os datasets em um classificador real
Após a finalização do desenvolvimento do software foi realizado um teste da ferramenta visando analisar sua efetividade na tarefa de criar datasets sintéticos de uso relevante em aplicações reais de aprendizado de máquina. Para tal, utilizamos o ABCDataset para gerar um dataset com 10 diferentes espécies de insetos. A escolha pelo uso de insetos advém da dificuldade de conseguir imagens reais destes animais devido à sua grande fragilidade e tamanho reduzido. Ao criar o dataset de teste foi utilizado apenas 1 modelo 3D para cada espécie de inseto e foram geradas 1000 imagens para cada uma delas.
Com o dataset gerado foi criado um modelo de rede neural de classificação, ou seja um modelo que ao receber uma imagem nunca antes vista seja capaz de identificar qual é a espécie de inseto que há na imagem. Para a criação do classificador utilizamos a linguagem de programação “Python” juntamente ao framework “Pytorch” (Pacote de bibliotecas para implementação de modelos de aprendizado de máquina).
É importante frisar que durante o processo de treinamento da rede neural, apenas imagens sintéticas criadas pelo ABCDataset foram utilizadas, sendo que 750 delas foram utilizadas no treinamento e as outras 250 foram separadas para utilização na etapa de teste de acurácia do classificador após o treinamento. Durante o período de testes, por sua vez, foram apresentadas ao classificador as 250 imagens sintéticas não vistas no treinamento, bem como outras 30 imagens reais dos insetos na natureza retiradas da internet. a ideia é analisar a taxa de acerto do classificador em identificar a espécie do inseto presente em cada imagem nova que recebe.
Durante o período de testes foram realizadas duas análises. A primeira testou a acurácia do classificador conforme o aumento do número de épocas de treinamento (número de vezes que as imagens de treinamento passam pelo classificador para que aprenda com elas). Importante frisar que durante o primeiro teste, o número de espécies de insetos foi mantido em 10 em todos os treinamentos. Na segunda análise, por sua vez, buscou-se testar como a acurácia do classificador seria afetada conforme o aumento do número de espécies de insetos. Para isso manteve-se o número de épocas em 10 para todos os treinamentos e variamos o número de espécies, iniciando com apenas 2 espécies e aumentado gradativamente de duas em duas até um máximo de 10.

Figura 2. Imagens artificiais em comparação com reais da respectiva classe. Cada coluna representa uma classe. As duas primeiras linhas representam imagens sintéticas e a terceira imagens reais. Fontes das imagens reais da esquerda para a direita [1,3,4,5,9,10].
Resultados dos testes de acurácia
Ao analisar os dados obtidos no primeiro teste podemos notar que a acurácia do classificador aumentou com o aumento do número de épocas de treinamento e como a reta de tendência ainda tende a subir, isso é um indicador de que se utilizarmos um número maior de épocas a acurácia ainda poderia aumentar, visto que ainda não atingiu seu pico (Figura 3 à esquerda). No entanto isso não foi feito devido a limitações computacionais do computador utilizado na pesquisa.
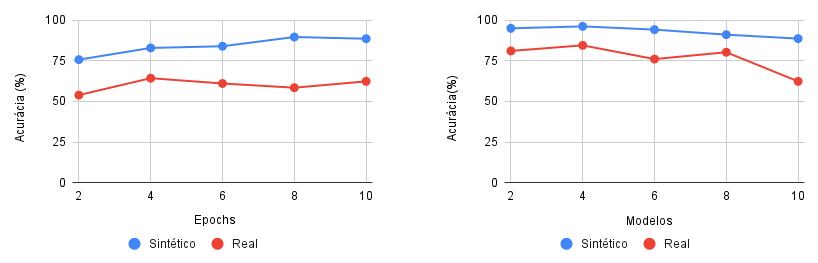
Figura 3. À esquerda uma análise sobre a acurácia da ResNet em identificar imagens sintéticas e reais com um aumento do número de épocas. À direita uma análise sobre a acurácia da ResNet em identificar imagens sintéticas e reais com um aumento do número de espécies de insetos.
Com relação ao segundo teste, observou-se que, como esperado, a acurácia do classificador caiu com o aumento do número de espécies de insetos. Ainda assim a queda não foi muito grande (Figura 3 à direita). Quando testada a acurácia do classificador para identificar imagens artificiais, este atingiu uma precisão de 96,2% no melhor caso. Quando testado com imagens reais esse mesmo modelo atingiu uma precisão de 84,5%.
Conclusões
Com os resultados obtidos, demonstramos que datasets criados com o ABCDataset podem sim atuar de maneira satisfatória quando aplicados em situações reais em modelos de classificação de imagens.
Com o nosso software, pesquisadores serão capazes de desenvolver de maneira simples e rápida seus próprios datasets, podendo desenvolver pesquisas com objetos de difícil obtenção de dados, sem a necessidade de gastar um tempo excessivo desenvolvendo os datasets da maneira tradicional, o que significa que mesmo sem possuir um grande conhecimento em computação gráfica, poderão realizar seus treinamentos em aplicações de todos os tipos, seja no reconhecimento de objetos por câmeras, aplicações em robótica ou qualquer outra área que necessite de datasets de imagens para treinamento, democratizando a implementação da RD e aumentando suas possibilidades.
Para casos onde altas precisões são requeridas este software não se mostrou muito eficaz, e isso provavelmente deriva do fato de que ao projetarmos o software para funcionar com o maior número de tipos de objetos possível, abrimos mão de especificidades que podem ser necessárias em cada caso específico. Ainda assim, no uso em tarefas onde a precisão necessária é menos estrita, o ABCDataset demonstrou uma performance satisfatória.
Agradecimentos
Agradeço imensamente ao meu orientador, prof. Dr. Bruno Augusto Dorta Marques por me aceitar como seu aluno, por compartilhar seu tempo e conhecimento comigo e por ter se disposto a me orientar mesmo quando lhe faltou saúde. Este trabalho jamais teria saído do papel sem sua ajuda. Muito obrigado.
Bibliografia
1. furret. https://www.inaturalist.org/photos/317597782, 2023. Acessado em 26/10/2023.
2. Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep Learning. MIT Press, 2016. http://www.deeplearningbook.org.
3. johnmarchant. https://www.inaturalist.org/photos/330374421, 2023. Acessado em 26/10/2023
4. manimiranda. https://www.inaturalist.org/photos/2444351, 2015. Acessado em 26/10/2023.
5. Show Ryu. Alcimocoris japonensis. https://commons.wikimedia.org/wiki/File:Alcimocoris_japonensis.JPG
6. Unity Technologies. Unity Real-time Development Engine. Unity, 2022. https://unity. com/.
7. Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world, 2017.
8. Jonathan Tremblay, Aayush Prakash, David Acuna, Mark Brophy, Varun Jampani, Cem Anil, Thang To, Eric Cameracci, Shaad Boochoon, e Stan Birchfield. Training deep networks with synthetic data: Bridging the reality gap by domain randomization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, páginas 969–977, 2018.
9. Royal Tyler. https://www.inaturalist.org/photos/131076733, 2021. Acessado em 26/10/2023.
10. Bruno Uehara. https://www.inaturalist.org/photos/160634566, 2021. Acessado em 26/10/2023.
Redes Sociais